Regulatory reporting analytics for fintech is the practice of building automated, auditable data pipelines that produce accurate compliance outputs — from AML transaction monitoring to capital adequacy reporting — directly from your data warehouse, without manual intervention. Done well, it transforms regulatory reporting from a quarterly fire drill into a continuous, low-effort operation that regulators can trust and your team can maintain.
If your compliance team is still exporting CSVs, pasting figures into Excel, and manually cross-checking numbers the week before a submission deadline, you are not alone — but you are increasingly exposed. <cite index="2-2">Fintech regulation in 2026 is more complex, more fragmented, and more actively enforced than it was just a few years ago.</cite> The businesses that will scale without regulatory friction are the ones that treat compliance reporting as a data engineering problem from the outset.
Why Fintech Regulatory Reporting Breaks at Scale
There is a specific failure pattern we see repeatedly at growth-stage fintechs. In the early days, regulatory reporting is manageable: one or two people know where the numbers live, they pull them manually, sense-check against memory, and submit. The regulator is happy. The team moves on.
Then the business scales. Transaction volumes triple. New products launch. The team adds headcount across multiple jurisdictions. And suddenly, the person who "just knows" how the AML report is built has left, the spreadsheet they maintained has seventeen tabs, three broken formula references, and no documentation. The numbers submitted last quarter cannot be reconciled to the ones submitted this quarter — and nobody can explain why they differ.
This is not a hypothetical. A pattern we see repeatedly in our work with early-stage payments and fintech companies: critical compliance calculations running in Excel that belong in SQL models inside a governed data warehouse. When the sheet breaks, the business goes blind at exactly the moment it can least afford to.
<cite index="8-3,8-4,8-5">Fintech companies face mounting regulatory pressure in 2026. Regulators demand stronger oversight of banking partnerships, tighter consumer protection standards, and more transparent compliance frameworks. Non-compliance can result in hefty fines, damaged reputations, and lost partnerships with traditional financial institutions.</cite>
The cost of getting this wrong is concrete. <cite index="13-26">Globally, regions including Asia-Pacific, Europe, the Middle East, Africa, Latin America, and North America invest a staggering $206 billion annually in adhering to financial crime compliance standards.</cite> A significant portion of that spend is pure operational waste — people manually doing work that a well-built data pipeline should be doing automatically.
📺 Watch: Course on Regulatory and Supervisory Technology (RegTech & SupTech). Link in Description

What "Regulatory Reporting Analytics" Actually Means in Practice
It is worth being precise here, because the term gets misused. Regulatory reporting analytics is not about buying a RegTech SaaS tool and plugging it in. It is about building the data infrastructure layer underneath your compliance function — the pipelines, models, and reporting surfaces that feed whatever submission system you use.
In practice, that means:
1. A governed data warehouse as the single source of truth. All transaction data, customer records, and event logs land in one place — typically BigQuery or AWS — and are transformed into clean, version-controlled models using dbt. No compliance calculation should be running outside the warehouse.
2. Validated, tested SQL models for each regulatory metric. AML thresholds, transaction monitoring rules, capital adequacy ratios, and suspicious activity flags should all be defined as SQL models with automated tests. If the underlying data changes shape — a field renames, a source adds a new transaction type — the test suite catches it before it corrupts a submission.
3. Audit-ready lineage and documentation. Regulators do not just want the number — they want to know where it came from. dbt's built-in lineage graph and documentation site make it possible to trace any compliance metric back to its raw source in minutes, not hours.
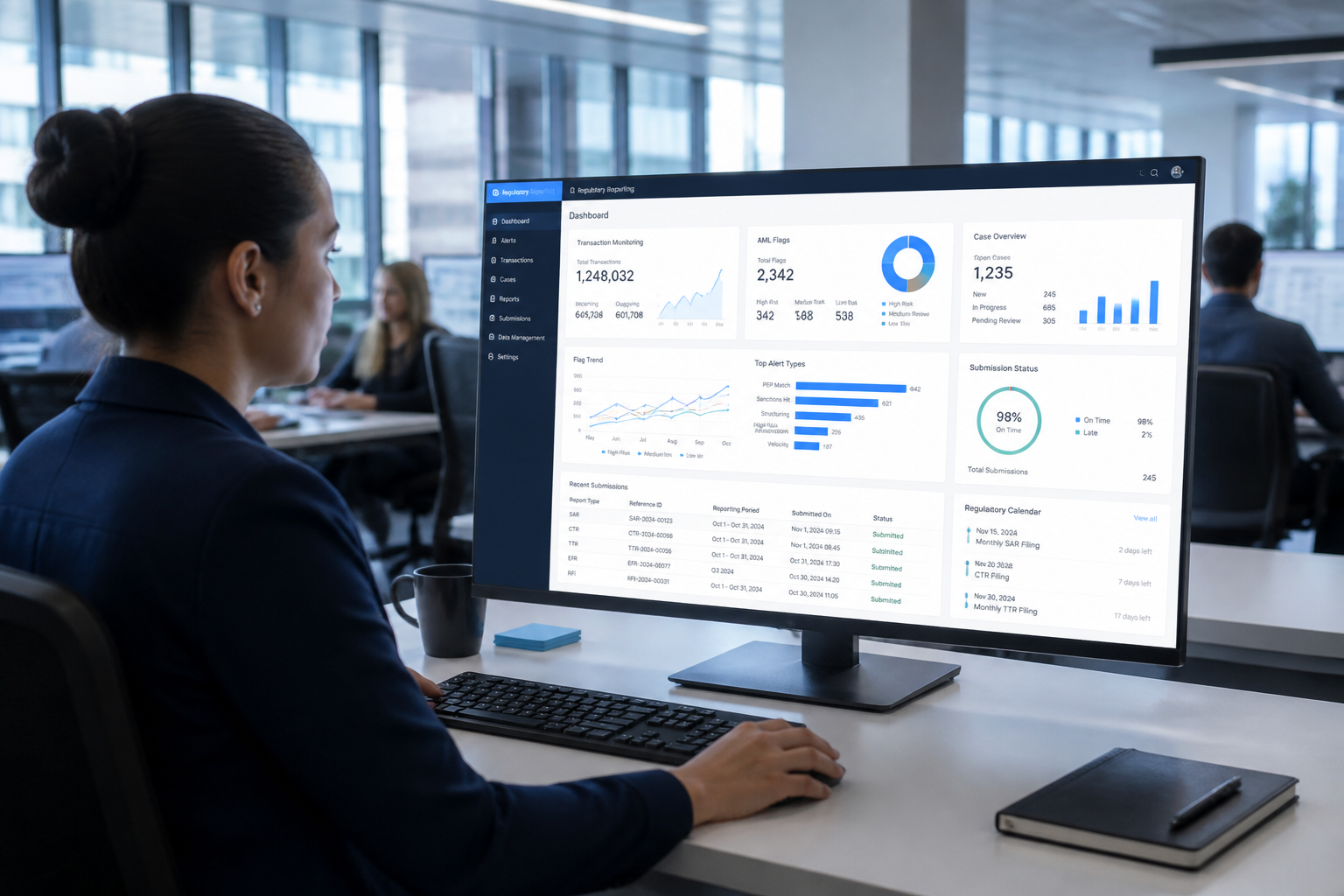
4. Automated, scheduled reporting surfaces. Compliance dashboards built in Holistics BI or Looker, refreshing automatically on the schedule your team needs — daily for transaction monitoring, monthly for capital reports, quarterly for regulator submissions — with no manual data extraction required.
A global fintech we worked with had a reconciliation process that a compliance analyst ran manually every week. It took 30–50 minutes and involved downloading three files, joining them in Excel, and checking the output by eye. We rebuilt it as an automated SQL pipeline in BigQuery. It now completes in under 3 seconds, runs on a schedule, and flags anomalies automatically. The analyst now reviews exceptions instead of building the report.
The Five Data Engineering Decisions That Determine Whether Your Compliance Infrastructure Holds Up
This is where most implementations go wrong — not in strategy, but in specific technical choices made early that become very expensive to unpick later.
Decision 1: Raw or transformed data in your compliance models? Always transform. Build staging models in dbt that standardise field names, cast data types, and apply business rules before any compliance logic touches the data. If a source system changes its date format or renames a column, you fix it once in the staging model — not in fifteen compliance calculations downstream.
Decision 2: One monolithic compliance model or modular marts? Modular, always. Build separate mart-layer models for transaction monitoring, customer risk scoring, and regulatory submission — each with its own test suite. A single monolithic model that produces all compliance outputs becomes untestable, undocumentable, and impossible to audit.
Decision 3: How do you handle historical point-in-time accuracy?
This is the question most teams do not ask until a regulator does. Compliance reports must reflect the state of data at the time of the reporting period, not the state as it exists today. If a customer's risk tier changed mid-quarter, your Q2 report should reflect what it was during Q2 — not what it is today. Implement snapshotting in dbt using dbt snapshot for slowly changing dimensions on any entity that feeds a regulatory calculation.
Decision 4: How do you document metric definitions?
Document in code, not in a wiki. Use dbt's schema.yml files to define every compliance metric — what it measures, how it is calculated, what the expected data range is, and which regulation it satisfies. This documentation lives alongside the code, is version-controlled, and auto-populates into dbt's documentation site. A regulator asking "how did you calculate this figure?" gets answered in minutes.
Decision 5: Who can change a compliance model, and how? Build a review process. Any pull request that modifies a model used in a regulatory calculation should require sign-off from both an engineer and a compliance stakeholder. This is not bureaucracy — it is the difference between a defensible audit trail and a compliance failure.
If you are unsure whether your current data infrastructure could support this kind of governance, explore how Fintel Analytics approaches this — we work with fintech businesses globally to design and deliver exactly this kind of data engineering foundation.
The Regulatory Landscape Making This Urgent in 2026
The compliance burden is not getting lighter. <cite index="1-8,1-9">From capital adequacy and operational resilience to ESG reporting, AI governance, and anti-money laundering, regulatory expectations now reach deep into financial institutions' technology stacks and operating models. Frameworks such as CRR III/CRD VI, DORA, PSD3, and the upcoming AMLA regime are already reshaping how banks and fintechs build, secure, and scale their systems.</cite>
<cite index="3-18,3-19">The EU's Digital Operational Resilience Act (DORA) became fully enforceable in January 2025. It mandates strong ICT risk management, third-party oversight, incident reporting, and regular resilience testing.</cite> For data teams, DORA has a direct implication: the data pipelines feeding your compliance reporting are now in scope for operational resilience requirements. If your AML reporting pipeline fails, that is an ICT incident that may need to be reported.
<cite index="1-18,1-19,1-20">The EU Artificial Intelligence Act introduces an entirely new compliance layer. While the regulation entered into force in 2024, its impact accelerates through 2025 and becomes fully enforceable for high-risk systems from August 2026. Many of the AI use cases common in fintech — including credit scoring, loan approval, fraud detection, and AML risk profiling — are explicitly classified as high-risk AI systems under the Act.</cite> If your transaction monitoring or risk scoring involves any ML model, you now need auditable model lineage, documented training data, and evidence of human oversight — all of which need to be surfaced through your data infrastructure.
<cite index="11-15">Financial institutions are projected to increase their investment in regulatory technology (RegTech) by 128% between 2023 and 2030.</cite> The smart investment is not in more RegTech vendors — <cite index="12-3,12-4">a hidden cost that has crept up on many institutions is what might be called "RegTech bloat" — an overgrown thicket of compliance vendors, tools, and systems that ends up increasing costs and complexity.</cite> The smarter investment is in the data infrastructure layer that all of those tools rely on.
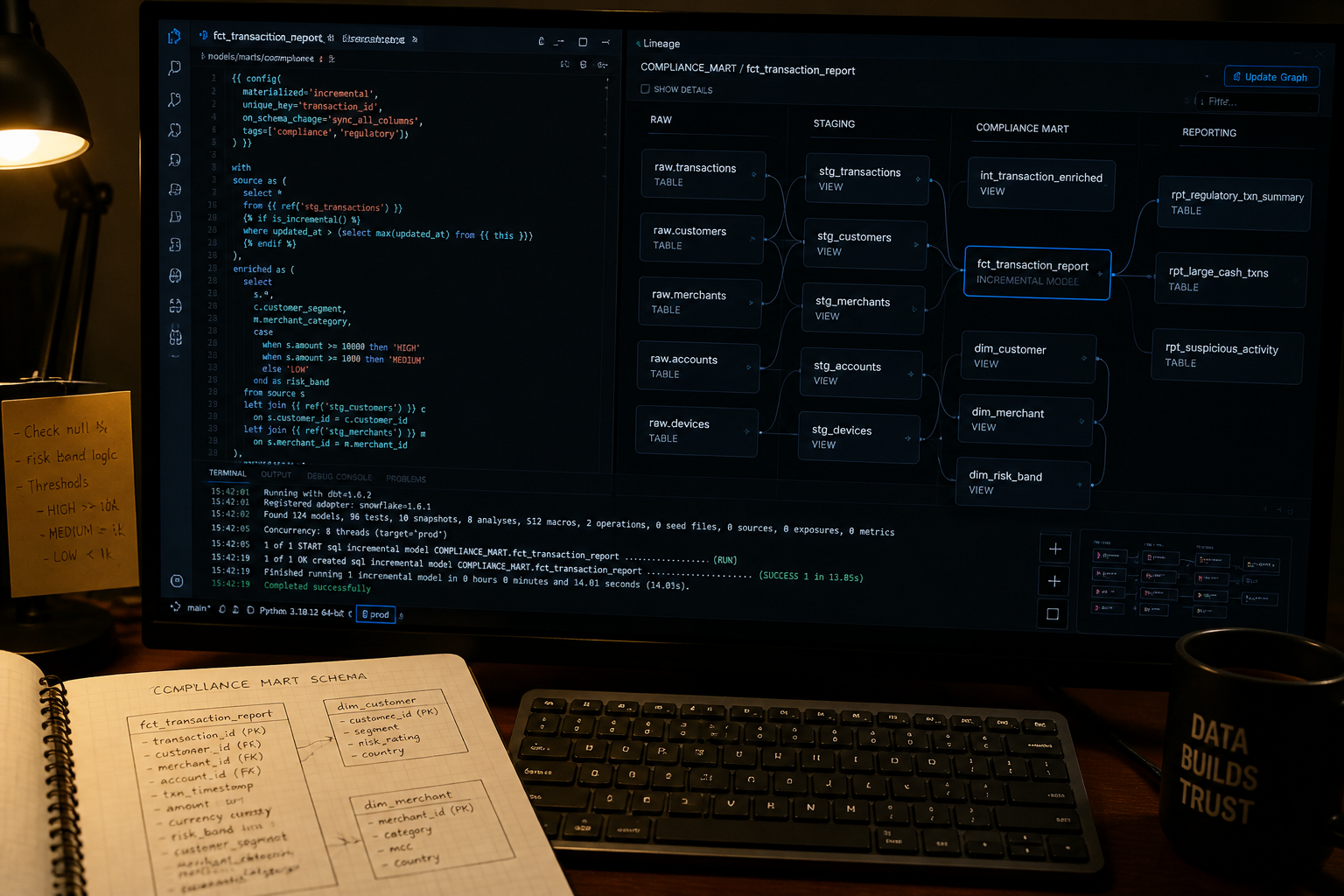
What an Audit-Ready Compliance Data Stack Actually Looks Like
Here is the architecture we recommend for Series A and Series B fintechs operating in regulated markets:
Ingestion layer: Raw transaction data, customer records, and third-party screening results land in BigQuery (or Redshift/Snowflake) via an ELT tool such as Fivetran or Airbyte. No transformation at this layer — preserve everything as it arrived.
Staging layer (dbt): Standardise field names, cast types, remove duplicates, apply source-level validations. Every model at this layer has automated tests: not-null constraints on primary keys, accepted-value tests on status fields, referential integrity checks across tables.
Intermediate layer (dbt): Business logic that is shared across multiple compliance outputs — customer risk tier assignment, transaction categorisation, entity resolution. This is where the heavy SQL lives. It is also where point-in-time snapshotting applies.
Mart layer (dbt): One mart per regulatory domain. An AML mart. A capital adequacy mart. A sanctions screening mart. Each mart is independently testable, independently documentable, and independently deployable.
Reporting layer (Holistics BI or Looker): Compliance dashboards for the compliance team. Automated submission reports for the regulator. Exception alerting for real-time transaction monitoring. All connected to the mart layer — no SQL written outside the warehouse.
For teams earlier in this journey — still deciding whether a data warehouse is warranted at all — our post on when a startup actually needs a data warehouse is worth reading first.
A capital reconciliation project we delivered for a Series A payments company uncovered a $25 million discrepancy that had gone undetected in manual processes. At market borrowing rates, that gap was costing over $6,000 per day. The fix was not a new RegTech tool — it was building the SQL models that made the discrepancy visible for the first time.
How to Prioritise When You Cannot Build Everything at Once
For most growth-stage fintechs, the honest answer is: you cannot build the full stack on day one. Here is how to sequence the work:
Phase 1 — Stabilise your highest-risk report. Identify the single regulatory submission where an error would be most consequential — typically AML transaction monitoring or your primary prudential return. Rebuild this report as a dbt model in your data warehouse. Add tests. Document it. This alone removes your most critical single point of failure.
Phase 2 — Establish the data foundation. With your highest-risk report stable, standardise your staging layer. Ensure all source data is landing cleanly, field names are consistent, and basic data quality tests are in place. This is the unglamorous work that makes everything else possible.
Phase 3 — Build the compliance dashboard. Surface your compliance metrics in a BI tool your compliance team can actually use — ideally with automated alerts for threshold breaches. The compliance team should be able to see the current state of every key metric without asking the data team.
Phase 4 — Extend to all regulatory domains. With the foundation in place and one domain working well, extend the same pattern to your remaining regulatory reporting areas. The second mart takes a fraction of the time the first one did, because the infrastructure is already there.
If your data engineering foundation is still being built, our post on DataOps for early-stage startups covers the pipeline reliability principles that underpin this kind of work.
Frequently Asked Questions
Q: What is regulatory reporting analytics in fintech?
A: Regulatory reporting analytics is the practice of using data engineering and business intelligence tools to automate the production of compliance reports — such as AML monitoring outputs, capital adequacy returns, and suspicious activity reports — directly from a governed data warehouse. The goal is to eliminate manual data extraction, reduce error rates, and produce an auditable trail from raw source data to submitted figure.
Q: How does dbt help with fintech compliance reporting?
A: dbt (data build tool) enables compliance teams to define regulatory metrics as version-controlled SQL models with automated data quality tests. Every calculation is documented, testable, and traceable to its source data. This makes it possible to answer a regulator's question about how a figure was produced in minutes rather than days, and ensures that any change to a compliance model is reviewed and recorded.
Q: What data infrastructure do I need for regulatory reporting automation?
A: At minimum: a cloud data warehouse (BigQuery or Redshift), a transformation layer (dbt) for defining and testing compliance models, and a BI tool (such as Holistics or Looker) for surfacing reports and alerts. Ingestion tooling such as Fivetran or Airbyte handles the movement of raw data from source systems into the warehouse. This stack supports full lineage, automated scheduling, and audit-ready documentation.
Q: How does DORA affect fintech data pipelines?
A: DORA (Digital Operational Resilience Act), enforceable from January 2025, requires financial entities to treat their data and technology infrastructure as in-scope for operational resilience requirements. This means compliance reporting pipelines need documented runbooks, failure alerting, recovery time objectives, and third-party oversight — the same rigour applied to customer-facing systems.
Q: Can a Series A fintech afford to build this kind of compliance data infrastructure?
A: Yes — and the more relevant question is whether it can afford not to. The cost of a well-architected dbt and BigQuery implementation is modest compared to the cost of a regulatory fine, a failed audit, or a team of analysts manually maintaining compliance spreadsheets. The Phase 1 approach described above — stabilising your highest-risk report first — means you can start delivering value in weeks, not months.
Manual regulatory reporting is not just inefficient — at the scale and scrutiny levels fintechs face in 2026, it is a material risk to your operating licence, your investor relationships, and your team's time. At Fintel Analytics, we have helped payments companies, neobanks, and cross-border financial services businesses build exactly this kind of compliance data infrastructure — from the first dbt staging models through to live compliance dashboards that run without human intervention. If your team is still building regulatory reports by hand, that is a fixable problem, and the fix pays for itself faster than most technology investments you will make this year.