When Does a Startup Need a Data Warehouse? A Practitioner's Decision Framework for 2026
A startup needs a data warehouse when spreadsheets and direct database queries can no longer support the speed or reliability of business decisions — typically when data comes from more than two or three sources, when more than one team needs consistent metrics, or when a single wrong formula is costing the business real money. The question is not whether you will eventually need one. It is whether you need one now — and getting the timing wrong in either direction is expensive.
This is one of the most common inflection points we see at Fintel Analytics. A founder comes to us with three dashboards showing three different revenue numbers, a finance team spending two hours every Monday rebuilding a spreadsheet that breaks whenever someone joins a new Slack channel, and an engineering team that is being asked to write ad-hoc SQL queries instead of shipping product. The tools have not scaled with the business. But neither has the thinking about what the business actually needs.
The wrong answer is almost always reached by asking the wrong question. The question is not "what data warehouse should we use?" It is "what decisions are we trying to make, and can our current setup support them reliably?"
Why Getting the Timing Wrong Costs More Than You Think
There are two failure modes, and both are genuinely painful.
Too early: A pre-seed company with two data sources and four team members stands up a full modern data stack — Fivetran ingesting from five tools, BigQuery, dbt with twenty models, Looker for BI. The infrastructure works. Nobody uses it. The engineering overhead of maintaining connectors and models consumes the one part-time analyst. Six months later, the founders are back to Google Sheets because "the data team is too busy maintaining the pipeline."
Too late: A Series A company with eight data sources, forty staff across four countries, and a finance team that cannot reconcile MRR between Stripe, their CRM, and their accounting system has been running on spreadsheets for two years past the point where it stopped being viable. Leadership is making fundraising projections from numbers that finance and operations do not agree on. The cost is not just the hours of manual reconciliation — it is the compounding cost of decisions made on bad data.
A 2025 report by the IBM Institute for Business Value found that 43% of chief operations officers identify data quality issues as their most significant data priority, and over a quarter of organisations estimate they lose more than USD 5 million annually due to poor data quality. Those figures reflect enterprise scale, but the proportional damage at growth-stage companies is often sharper — because there are fewer people to catch errors, and decisions move faster.
The 1x10x100 principle is worth keeping in mind here. The cost of addressing a data quality issue at the point of entry is approximately 1x the original cost. If the issue goes undetected and propagates through the system, that rises to 10x. If poor data reaches the decision-making stage, the cost can escalate to 100x the initial expense — through operational disruption, lost opportunities, and customer dissatisfaction. In a startup context, a formula error in a spreadsheet that informs a pricing model or a fundraise model is precisely this kind of cascading failure.
📺 Watch: Database vs Data Warehouse vs Data Lake | What is the Difference?

What Does a Startup's Data Actually Look Like at Each Stage?
The honest answer is that most early-stage startups do not have a data problem. They have a coordination problem dressed up as a data problem. Understanding the difference is the first step toward spending the right amount on infrastructure.
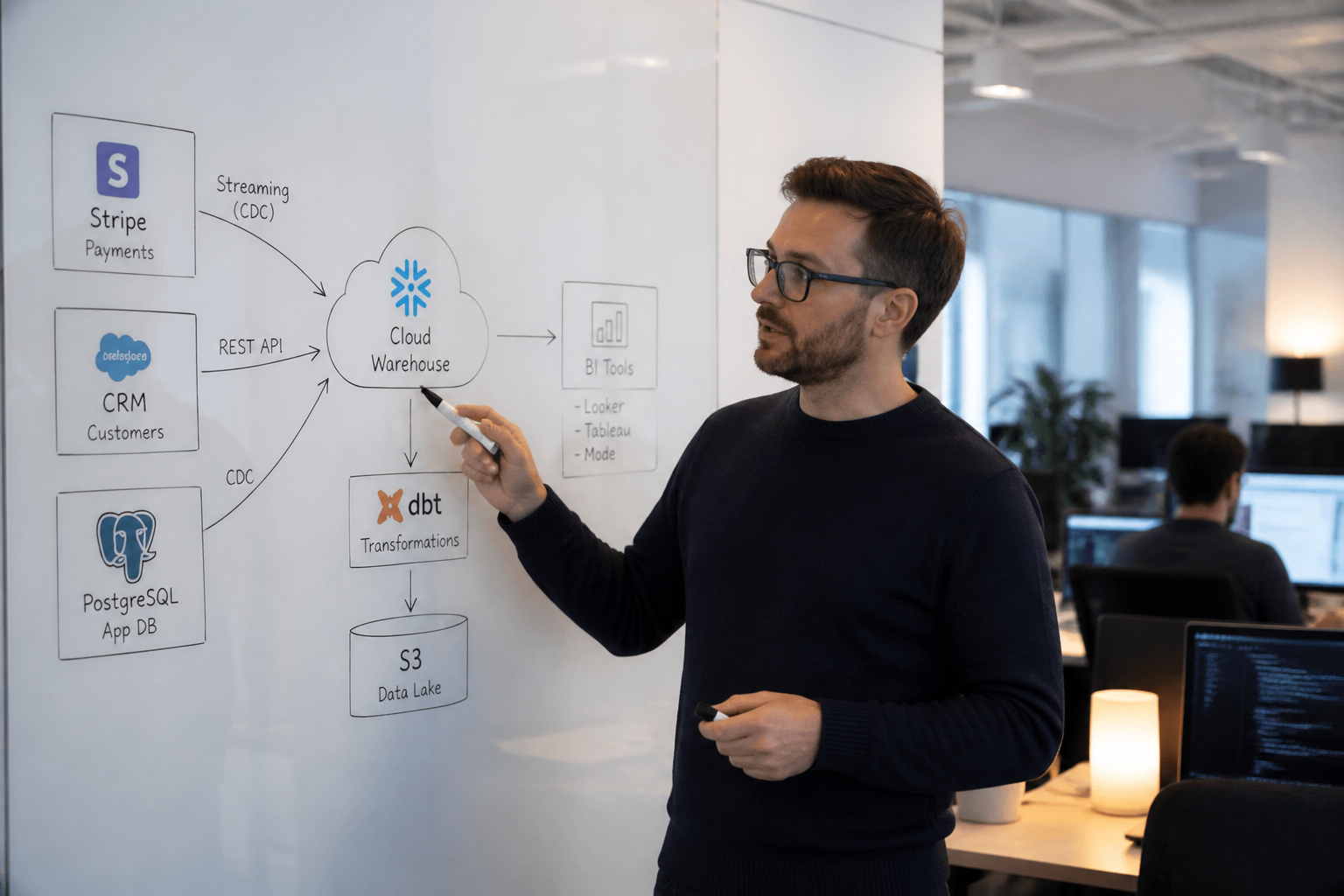
Pre-seed / seed (0–15 people, 1–2 data sources): At this stage, a startup's data often begins in fragments — user information lives in a production PostgreSQL database, payment data sits in Stripe, marketing analytics are in HubSpot, and crucial business metrics are tracked in a series of spreadsheets. The need for a single source of truth becomes clear quickly, but the path forward is not.
The honest answer for most companies at this stage: you do not need a data warehouse yet. You need clean, documented spreadsheets and a shared definition of your five most important metrics. A well-structured Google Sheet that three people understand is more valuable than a BigQuery project that nobody maintains.
Post-seed / early Series A (15–40 people, 3–5 data sources): This is where the cracks start showing. You have Stripe, a CRM, a product database, maybe an ad platform, and someone has been pulling data from each one manually every Monday. The spreadsheet has grown to forty tabs. Two people are maintaining it. Neither fully understands the other's formulas.
This is the most common point at which the cost of not acting starts to exceed the cost of acting. A pattern we see repeatedly at this stage: the same metric showing different numbers in different outputs — finance says one thing, operations says another, and leadership does not know who to believe. There is no single source of truth, no governance, and no documentation. The company is making board-level decisions from numbers that have not been validated against a common definition.
At this stage, you need at minimum: a cloud data warehouse (BigQuery is the simplest entry point for most teams), a lightweight ELT tool to pull from your core sources, and dbt to define and document your metrics in code. This does not have to be expensive. BigQuery has no cluster to manage, pricing is largely consumption-based at roughly $6.25 per TB scanned on the on-demand model, and it is the natural choice for any team already on Google Cloud.
Late Series A / Series B (40–150 people, 5+ data sources): By this stage, the question is not whether to have a warehouse — it is whether what you have built is actually fit for purpose. The default stack recommended for companies in the $5M to $50M ARR range is Fivetran or Airbyte for ingestion, BigQuery or Snowflake as the warehouse, dbt for transformation, and a BI tool like Metabase, glued together with a lightweight orchestrator.
At this stage the risks shift from "we have no infrastructure" to "we have infrastructure that was built too quickly and is now fragile." We regularly audit stacks at Series B companies where critical calculations still live in spreadsheets that sit outside the warehouse — where a formula in a Google Sheet is feeding a metric into a dashboard, meaning the model in dbt and the number on the slide deck are calculated differently. The dashboard is technically correct. The business is making decisions from the slide deck.
The Four Signals That Tell You It Is Time
Rather than picking a headcount threshold or funding stage as your trigger, use these four operational signals. When two or more are present simultaneously, the cost of delay is almost certainly exceeding the cost of building.
Signal 1 — The Monday morning spreadsheet. Someone on your team spends more than 30 minutes every week manually pulling, cleaning, and reformatting data before anyone can use it. That task is entirely automatable, and every week you do not automate it is a week of compounding debt. We rebuilt one reconciliation process that was taking 30–50 minutes to run as an automated SQL pipeline — it now completes in under 3 seconds.
Signal 2 — The number disagreement. Two people in the same meeting cite the same metric and get different answers. This is not a people problem. It is a data architecture problem. It means your metric definitions are not codified anywhere trustworthy, and it will get worse, not better, as you hire.
Signal 3 — The analyst bottleneck. Every data question — whether it is from finance, product, operations, or leadership — is routed through one person who can run SQL queries. That person is a single point of failure, a bottleneck, and almost certainly leaving within 18 months because the job has become thankless.
Signal 4 — The data request backlog. Engineering is fielding more than two or three ad-hoc data requests per week. Product is asking for user behaviour data. Finance is asking for cohort revenue. Operations is asking for fulfilment rates by region. None of these should require engineering time if you have the right infrastructure.
If you recognise more than two of these signals in your organisation right now, explore how Fintel Analytics approaches this — we work with pre-seed through Series B companies globally to design and deliver exactly this kind of infrastructure, scoped to the stage you are actually at rather than the one you are planning for.
What Stack Should You Actually Build?
The most dangerous advice in the modern data stack world is the advice to build what a large, well-resourced data team can maintain. The most common mistake a startup can make is to over-engineer its initial data stack — choosing a solution built for an enterprise that does not yet exist.
Here is a pragmatic, stage-appropriate framework based on what we actually deliver for clients:
Stage 1 — Seed, 1–2 sources, no dedicated data person: Do not build a warehouse yet. Document your metric definitions in a shared wiki. Use a structured Google Sheet or Notion database as your reporting layer. Make sure your five core metrics have agreed definitions that everyone can access. The goal is alignment, not infrastructure.
Stage 2 — Early Series A, 3–5 sources, part-time data or analyst resource: Stand up BigQuery (or Snowflake if your team has experience with it). Use Fivetran or Airbyte for ingestion from your critical sources. Introduce dbt with a small number of clearly defined models — start with revenue, active users, and churn. Connect a lightweight BI tool. Holistics BI is an excellent choice at this stage: it is cost-effective, self-service friendly, and purpose-built to support a SQL semantic layer, which means your metric definitions stay in code and do not drift into dashboards. (Fintel Analytics is an official Holistics BI partner, and we have deployed it successfully for growth-stage companies across fintech, e-commerce, and financial services.)
A note on cost: an enterprise stack combining Snowflake, Fivetran, dbt, and Looker typically runs $5,000–$20,000 or more per month. For most early Series A companies, this is not justifiable. The right stack at this stage should cost a fraction of that in tooling, with the investment going into well-scoped implementation rather than vendor licensing.
Stage 3 — Series A / B, 5+ sources, dedicated data function: Expand your dbt model layer methodically. Implement a proper staging → intermediate → mart layer structure. Introduce data tests and documentation at the model level. Add orchestration (Airflow, Prefect, or Cloud Composer) to manage pipeline dependencies. At this stage, the questions shift from "does the data exist?" to "is the data trustworthy?" — which means investing in data quality checks, lineage documentation, and an agreed process for promoting changes.
For a closer look at how the metrics layer fits into this, our post on SQL Semantic Layer: Why Your Metrics Are Broken in 2026 covers the most common failure mode at this stage in detail.
The most expensive failure mode in 2026 is also the most avoidable: a team adopts multiple tools without named, weekly-frequency use cases for each. Six months later, the tools are paid for, partially configured, and not actually changing anything in the business. The discipline is to name the business decision the tool unblocks before buying.
The Real Cost of Waiting Too Long
Let us be specific about what late looks like, because founders often underestimate the true cost of deferred infrastructure investment.
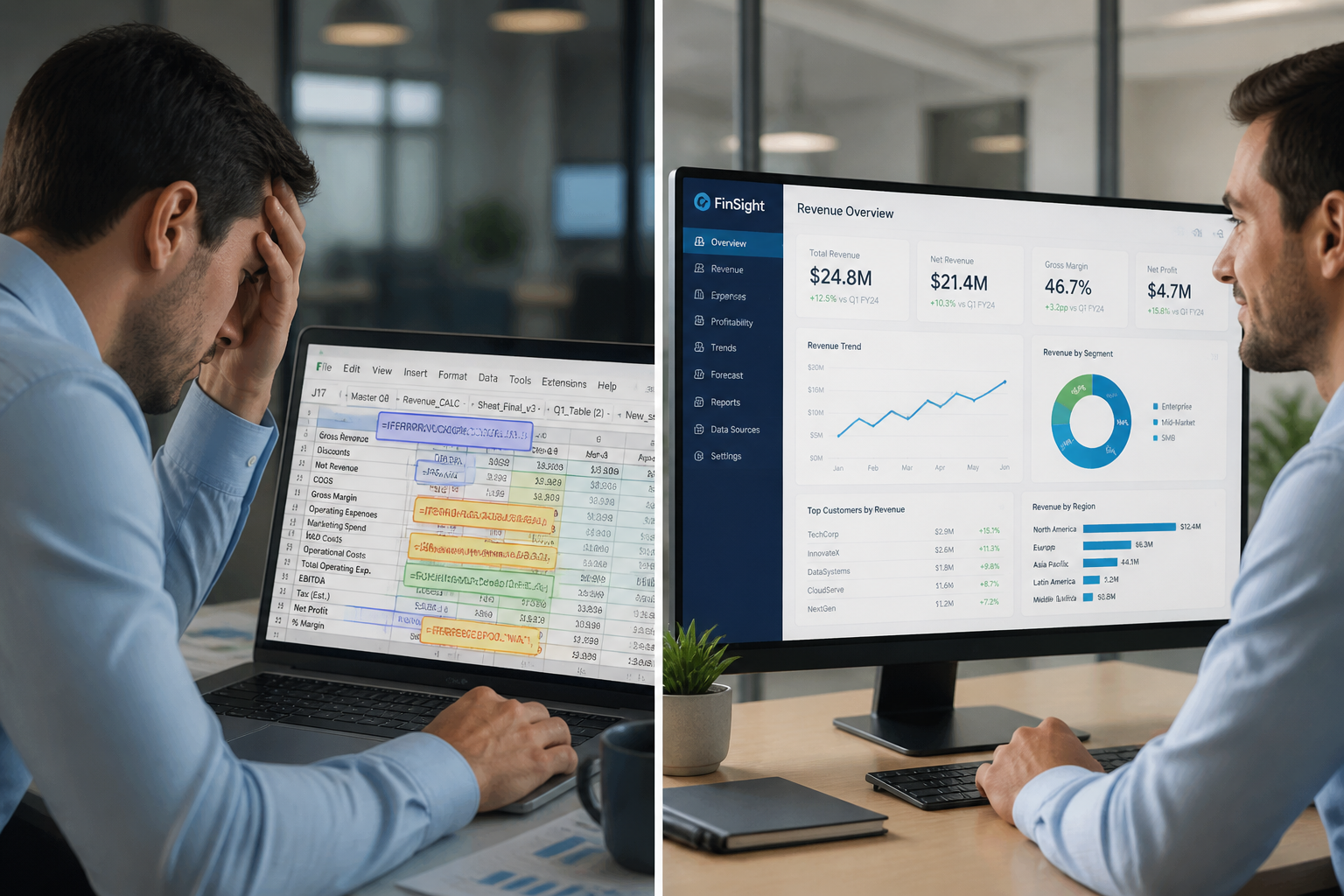
We worked with a Series A fintech that had been running its core financial reporting entirely from Google Sheets for two years past the point where that was defensible. By the time they engaged us, weekly executive reporting required 90 minutes of manual work every Friday — data pulled from four tools, reformatted, cross-referenced, and pasted into a slide deck. That is 78 hours per year of a senior analyst's time, for a report that was frequently wrong anyway because the pull process introduced human error.
We replaced it with a live dashboard that updates hourly, requires zero manual effort, and is now used by the board in quarterly reviews. The hours freed up went back into actual analytical work — the kind that surfaces trends, identifies risks, and informs strategy.
The more serious version of this problem involves financial accuracy. In a capital reconciliation engagement with a global fintech, building the right data infrastructure to model positions correctly uncovered a $25M discrepancy that had gone entirely undetected in the spreadsheet-based process. At market borrowing rates, that gap was costing more than $6,000 per day.
This is what deferred infrastructure debt actually costs. It is not the tool licensing. It is the decisions made on bad numbers while you waited to fix it.
The warehouse is where your raw data lands and where every downstream tool reads from. It is the single most consequential decision in the stack, because switching warehouses later is genuinely painful. Get the timing right, and the warehouse becomes a growth accelerator. Get it wrong — either too early or too late — and it becomes a cost centre that nobody trusts.
For further reading on how the operational layer connects to your financial reporting, see our post on Financial Close Analytics: Cut Your Month-End Close in 2026, which covers the specific failure modes we see most often at month-end.
Frequently Asked Questions
Q: When should a startup build a data warehouse?
A: The clearest signal is when your business draws data from three or more sources and at least two teams need to report on the same metrics consistently. If manual data preparation is consuming more than 30 minutes per week, or if the same metric produces different answers in different tools, the cost of not building has exceeded the cost of building. For most startups, this occurs somewhere between the post-seed and early Series A stages.
Q: What is the best data warehouse for a startup in 2026?
A: For most growth-stage companies, BigQuery is the simplest entry point — no cluster management, consumption-based pricing, and strong integration with dbt and common ELT tools. Snowflake is a strong alternative if your team has existing experience with it. The most important factor is not which platform you choose, but whether your team can operate and govern it without hiring a specialist cluster administrator.
Q: How much does a startup data stack cost to build and run?
A: At the early Series A stage, a well-scoped stack using BigQuery, a managed ingestion tool, dbt, and a mid-tier BI tool can run well under $1,000 per month in tooling. The dominant cost is implementation and ongoing maintenance, not licensing. Enterprise-grade stacks combining Snowflake, Fivetran, dbt, and Looker can reach $5,000–$20,000 per month — and are generally not appropriate until Series B or later.
Q: Can a startup use spreadsheets instead of a data warehouse?
A: Yes — and for many pre-seed and early seed companies, that is the right answer. Spreadsheets become a liability when they are the source of record for metrics that multiple teams depend on, when they require frequent manual maintenance, or when they lack the validation and version control needed to be trusted. The goal is not to eliminate spreadsheets, but to stop using them for tasks that belong in a governed data layer.
Q: How long does it take to implement a startup data warehouse?
A: A focused implementation — warehouse setup, two to four core data source integrations, a dbt model layer covering your primary metrics, and a BI layer — can be delivered in four to eight weeks when scoped correctly. The most common cause of delays is unclear metric definitions and undocumented business logic, not the tooling itself. Starting with five well-defined, agreed metrics is more valuable than starting with fifty loosely defined ones.
If you are a founder or CTO asking whether your current setup is still serving your business — or whether you have passed the point where it is doing more harm than good — the answer is almost always clearer than it feels from the inside. At Fintel Analytics, we have helped growth-stage companies at pre-seed through Series B design and implement data infrastructure that is matched to their actual stage, scoped to deliver value quickly, and built to scale without being rebuilt. If your team is still making critical decisions from spreadsheets, manual reports, or dashboards that disagree with each other, that is a fixable problem — and fixing it pays for itself.