API analytics for fintech companies means systematically capturing, modelling, and visualising the data your APIs generate — response times, error rates, call volumes, provider behaviour — and using it to drive operational decisions, not just debug outages. For growth-stage payments and fintech businesses, the API layer is where revenue either flows or leaks, and most companies have no structured analytics sitting on top of it.
If that sounds like a niche engineering concern, consider this: every failed API call in a payments flow is a transaction that did not complete. Every provider degradation that goes undetected for 20 minutes is 20 minutes of customer drop-off you will never recover. And yet, in practice, the majority of Series A and Series B fintech companies we work with are monitoring their APIs with a basic uptime check and a Slack alert — and calling that observability.
The gap between what your API layer knows and what your business can actually act on is a data engineering problem. This post explains exactly how to close it.
Why Fintech API Data Is a Business Intelligence Problem, Not Just a DevOps One
The standard framing of API monitoring is infrastructure: is the endpoint up, is latency within SLA, did the last deploy break anything? That framing is correct but incomplete. For a fintech or payments company, your API layer is also the most granular, real-time record of your business operations in existence.
Think about what lives in your API logs if you are running a payments platform:
- Every payment initiation, including which provider it was routed to and whether it succeeded
- Every authorisation decline, with the raw decline code from the card network or bank
- Every webhook delivery, including retry counts and latency per downstream consumer
- Every open banking data pull, including which institutions timed out or returned stale data
- Every third-party KYC or fraud check, including response time and outcome
None of this is accessible by default in a Grafana dashboard or a Datadog alert. It lives in logs, event streams, and raw API response payloads — and unless it has been deliberately modelled into a data warehouse and surfaced through a BI layer, your finance team, your operations team, and your leadership team cannot see it.
The consequence is what we call the "invisible failure" problem. A provider degradation that lifts your payment failure rate from 1.2% to 4.8% over 40 minutes will not trigger most infrastructure alerts because the endpoint is technically up and latency is within threshold. But your revenue impact is immediate, measurable, and preventable — if you have the analytics in place to catch it.
Open banking API call volumes are forecast to grow 427% globally between 2025 and 2029, according to 2026 research — from 137 billion to 720 billion annual calls. The businesses that build structured analytics on top of that volume now will have a material operational advantage over those that are still parsing logs manually when scale makes that impossible.
📺 Watch: Skills for RegTech/FinTech Product Managers | Product Manager – RegTech/FinTech Course

What "Good" API Analytics Actually Looks Like in Practice
The first thing to get right is the distinction between monitoring and analytics. Monitoring is reactive: you define known failure conditions and alert when thresholds are breached. Analytics is something different — it is the structured, queryable, historically-comparable record of how your API layer behaves over time, enriched with enough business context to answer questions like:
- Which payment provider has the highest success rate for UK Visa debit cards between £50 and £500?
- How does our webhook retry rate correlate with downstream partner SLA violations?
- Which merchant segments experience the highest API timeout rate, and at what time of day?
- What is the P99 latency distribution for our KYC check API, segmented by applicant country?
None of these questions can be answered from an infrastructure monitoring tool. They require your API event data to be:
- Captured at the right granularity — individual request/response events, not aggregated metrics
- Landed into a structured data warehouse (BigQuery or AWS Redshift are typical for companies at this scale)
- Modelled with dbt into clean, queryable, business-contextualised tables — joining API events to payment records, customer records, and provider configuration
- Surfaced through a semantic layer so that non-technical users in finance, operations, and product can query the data without writing SQL
A pattern we see repeatedly with early-stage fintech companies is that step one and step two happen organically — logs go somewhere, usually CloudWatch or a log aggregator — but steps three and four never happen. The data exists but it is not modelled, not joined to business entities, and not queryable. It sits in a log store that only engineers can access, via queries that take minutes to run and produce output no-one in the business knows how to interpret.
The result is that operational decisions — which provider to route to, which integration to prioritise fixing, which partner is underperforming against SLA — get made from memory, from weekly engineering updates, or from gut feel. That is a fixable problem.
The Five API Metrics That Actually Matter to a Fintech Business
Not all API metrics have equal business value. Engineering teams tend to track what is easy to instrument; finance and operations teams care about something different entirely. Here is the framework we use when scoping API analytics for a payments or fintech client, mapped to the business question each metric answers.
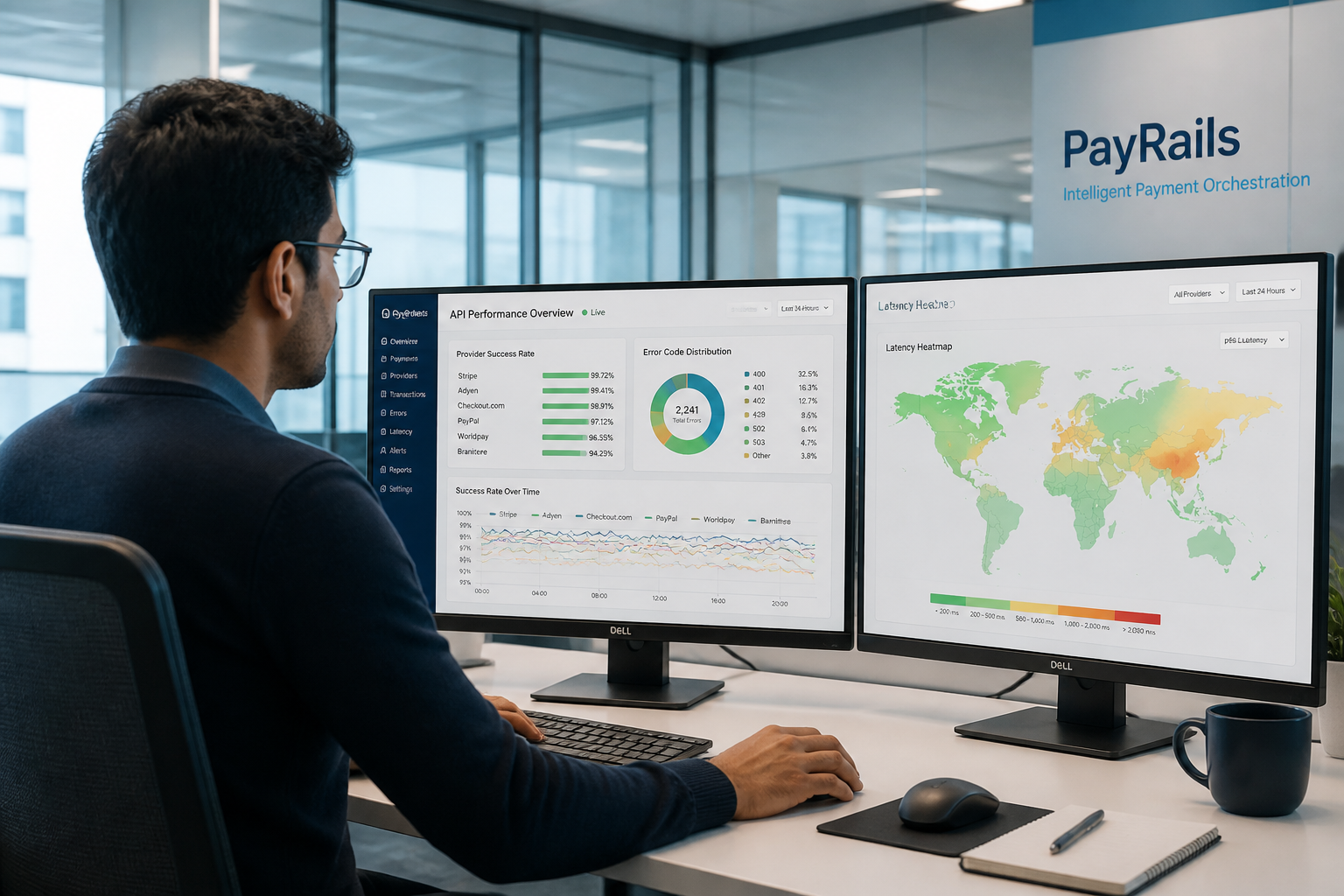
1. Provider-Level Payment Success Rate (PSR) Not the blended success rate across all providers — the per-provider, per-card-scheme, per-country breakdown. This is the metric that drives routing decisions and provider SLA enforcement. A blended PSR of 97.3% can hide a specific provider delivering 88% success on European debit transactions, which is where you are routing 40% of your volume.
2. Error Code Distribution Raw decline codes from card networks, banks, and third-party providers tell you whether failures are recoverable (retry will succeed) or terminal (card blocked, insufficient funds). Tracking error code distribution over time, segmented by provider and transaction type, is the foundation of any intelligent retry strategy and feeds directly into revenue recovery models.
3. API Tail Latency (P95/P99) Mean latency is misleading. The 1% of requests that take 10x longer than average are disproportionately the ones causing user abandonment at checkout and integration timeout errors for API consumers. For a payments company processing thousands of transactions per hour, P99 latency is a revenue metric, not just a performance one.
4. Webhook Delivery Success Rate For any fintech with downstream API consumers — whether that is merchants, lending platforms, or embedded finance partners — webhook reliability is part of your product. A delivery success rate below 99% means partners are building compensating logic, duplicating effort, and eventually deprioritising your integration. Tracking this at the per-consumer level, with retry chain visibility, turns an engineering metric into a partnership health indicator.
5. Third-Party Dependency Uptime and Latency Your payment success rate is partly a function of your own code and partly a function of the reliability of every third-party API in your stack — card networks, KYC providers, fraud engines, open banking APIs. Modelling the uptime and latency of each dependency separately, and correlating it with your own outcome metrics, is the only way to definitively answer "was that spike in failures ours or theirs?"
If you are looking to implement this kind of structured API analytics capability in your organisation, explore how Fintel Analytics approaches this — we work with fintech and payments businesses to design and deliver exactly this kind of data engineering solution, from raw event capture through to live operational dashboards.
How to Actually Build This: The Data Engineering Architecture
The implementation pattern for API analytics at a growth-stage fintech follows a consistent architecture, regardless of whether you are on AWS or GCP. Here is what we typically build and why each layer exists.
Event Capture Layer
Before any analytics is possible, you need a reliable mechanism to capture API events at request/response granularity. The two common approaches are structured application logging (writing a structured JSON log entry for every API call, including request parameters, response code, latency, and key business identifiers) and event streaming (publishing API events to a Kafka topic or an AWS Kinesis stream in real time).
The choice between these depends on your latency requirements. For most fintech analytics use cases, structured logging into a log aggregator with a nightly export to your data warehouse is sufficient. For real-time alerting on provider degradation — the "invisible failure" scenario described above — event streaming is necessary.
Critically, the log schema matters enormously. We have worked with companies where years of API logs exist but contain no business-context fields — no merchant ID, no product type, no routing decision identifier — making it impossible to segment by anything meaningful. Log schema design is an analytics decision, not just an engineering one.
Transformation Layer (dbt)
Raw API event logs land in your warehouse as flat, denormalised records. dbt is where you turn that into something a business can use. A typical dbt model structure for API analytics looks like:
stg_api_events— cleaned, typed raw events with consistent field namingint_payment_attempts— API events joined to payment records, enriched with provider and routing configurationint_provider_performance— aggregated provider metrics (PSR, P99 latency, error distribution) by time window, card scheme, and geographyfct_payment_outcomes— the final business-facing fact table linking every payment attempt to its outcome, route, and customer contextfct_webhook_delivery— webhook events joined to downstream consumer records, with retry chain modelling
Migrating this kind of logic into dbt models — rather than leaving it in ad hoc SQL scripts or, worse, spreadsheet formulas — eliminates a class of recurring manual errors and creates a versioned, testable, auditable record of how every metric is defined. In our experience working with fintech companies, this migration typically cuts weekly maintenance time significantly and dramatically improves the trust finance and operations teams place in the numbers.
Semantic Layer and BI
The final layer is where business users interact with the data. A well-designed semantic layer — built on Holistics BI or Looker — means a head of payments operations can answer "did our primary provider degrade between 14:00 and 14:40 yesterday, and what was the revenue impact?" without raising a ticket with the data team. Metrics are pre-defined, consistently calculated, and filterable by the dimensions that matter to the business.
This is the layer that most early-stage companies are missing entirely. The data exists, the models may partially exist, but there is no business-accessible interface that makes the insights available to the people who need to act on them.

A Real-World Example: What API Analytics Uncovered for a Payments Company
A Series A payments company processing cross-border transactions had been managing provider performance through a combination of engineering intuition and monthly review meetings with account managers. They had no structured data on provider performance beyond a blended success rate figure in their basic monitoring dashboard.
When we built out their API analytics stack — structured event capture, a dbt model layer in BigQuery, and a live operational dashboard in Holistics BI — the first thing that became visible was a specific pattern: one of their three primary card acquirers was delivering a payment success rate 6.2 percentage points below the next-best provider for a specific corridor, but only for transactions above a certain value threshold. The blended success rate had been obscuring this because high-volume, low-value transactions with that provider were performing adequately.
That single insight, which had been invisible in the previous reporting setup, was worth a measurable improvement in authorisation rates on that corridor once routing was adjusted. The operational dashboard — which updated every hour from the live BigQuery layer — gave the payments operations team the ability to detect similar provider-specific degradations in near-real time, rather than discovering them through customer complaints or end-of-month reporting.
The infrastructure build took weeks, not months. The impact was immediate because the data had always existed — it just had not been modelled and surfaced in a way the business could act on.
This mirrors the pattern we have documented elsewhere: a reconciliation process that once took 30–50 minutes to run was rebuilt as an automated SQL pipeline and now completes in under 3 seconds. Weekly executive reporting that required 90 minutes of manual effort was replaced by a live dashboard updated hourly. The common thread is not the specific tools — it is the deliberate decision to treat operational data as a structured, queryable, business-facing asset.
When Should a Growth-Stage Fintech Prioritise API Analytics?
This is a question we get asked often, and the honest answer is: earlier than most companies think, but not immediately at pre-seed. Here is a practical decision framework.
Pre-seed / early seed: Focus on structured logging from day one. The cost is low — a few hours of engineering time to ensure your API logs are structured (JSON, not plaintext) and include the right business context fields. This pays dividends at every subsequent stage because you will have historical data to analyse. Do not build the analytics layer yet.
Late seed / Series A: This is typically the inflection point. You are processing meaningful transaction volume, you have multiple payment providers or integration partners, and the cost of not knowing which providers are underperforming is measurable in revenue terms. Build the data warehouse layer and basic dbt models. A basic provider performance dashboard at this stage will directly inform commercial conversations with providers and routing strategy decisions.
Series B and beyond: At this stage, incomplete API analytics is a risk management problem, not just an operational inconvenience. You will have SLAs with enterprise clients that your own reporting cannot verify. You will have regulatory obligations (particularly under frameworks like DORA in the EU, which came into full effect in 2025) that require documented evidence of third-party service provider resilience. You need the full stack: real-time event capture, a mature dbt model layer, semantic layer access for non-technical users, and automated alerting on provider degradation.
The companies that wait until Series B to start building this find themselves doing significant retrospective work to reconstruct historical patterns from degraded log data. The companies that lay the foundations at seed stage find the Series B build is an extension of something already working, not a rebuild from scratch.
If your team is also grappling with the downstream effects of unreliable API data — including issues with payment reconciliation and cash flow visibility — it is worth reading how structured data pipelines address payments reconciliation at scale and how cash flow forecasting analytics can be improved once the underlying event data is reliable.
Frequently Asked Questions
Q: What is API analytics for fintech companies?
A: API analytics for fintech means capturing, modelling, and visualising the data generated by your API layer — payment outcomes, provider performance, error distributions, webhook delivery rates — and making it queryable by business users. It is distinct from infrastructure monitoring, which only tells you whether an endpoint is up. API analytics tells you what is happening commercially inside your API traffic, and why.
Q: How is API analytics different from API monitoring?
A: API monitoring is reactive and infrastructure-focused — it alerts you when a known threshold is breached (e.g. latency exceeds 2 seconds). API analytics is proactive and business-focused — it gives you a structured, historical, segmentable view of API behaviour so you can answer questions like "which provider performs best for high-value EU transactions" or "what is the P99 latency for our KYC API by applicant country?" Most companies need both, but analytics is the layer that drives business decisions.
Q: What data engineering stack is typically used for fintech API analytics?
A: A typical stack for a growth-stage fintech includes structured event logging into a cloud data warehouse (BigQuery on GCP or Redshift on AWS), dbt for transformation and business logic modelling, and a BI tool such as Holistics or Looker for the semantic layer and dashboards. For real-time alerting on provider degradation, Kafka or AWS Kinesis is added for event streaming before the warehouse layer.
Q: How much does it cost to build API analytics for a Series A fintech?
A: The infrastructure cost is typically modest — BigQuery and dbt are inexpensive at Series A data volumes. The primary investment is in data engineering time to design the log schema, build the dbt model layer, and configure the BI tool. A well-scoped project can deliver a production-ready API analytics stack in four to six weeks. The ROI is typically visible within the first billing cycle through improved routing decisions, faster provider incident detection, and reduced manual reporting effort.
Q: What regulatory requirements make API analytics important for fintech companies?
A: In the EU, the Digital Operational Resilience Act (DORA), which came into full effect in January 2025, requires financial entities to monitor, classify, and report on ICT-related incidents and third-party service provider resilience. Structured API analytics — particularly third-party dependency monitoring — directly supports DORA compliance by providing the documented, auditable evidence of provider performance that regulators require.
If your payments or fintech business is making routing decisions from blended dashboards, detecting provider failures through customer complaints, or relying on engineering judgment to manage third-party API performance, that is a data problem with a known solution. At Fintel Analytics, we have helped Series A and Series B fintech and payments businesses build structured API analytics capabilities — from log schema design through to live operational dashboards that give payments operations, finance, and leadership the real-time visibility they need to make confident decisions. The data your API layer generates every second is already there — the question is whether you are using it.