Payments reconciliation analytics is the discipline of using automated data pipelines, SQL models, and BI tooling to continuously verify that every transaction recorded internally matches what actually settled externally — across PSPs, banks, and payment networks. Done properly, it replaces a fragile manual process with an always-on control layer that catches discrepancies in minutes rather than days. Done poorly — or not at all — it quietly compounds into capital risk, compliance exposure, and a finance team spending every week firefighting spreadsheet errors instead of doing actual analysis.
If you are building or scaling a payments business, reconciliation is not a back-office admin problem. It is a data infrastructure problem. And like most data infrastructure problems, it looks manageable at low volume and catastrophic at scale.
Why Manual Reconciliation Breaks at Fintech Scale
The pattern is remarkably consistent across the companies we work with. At launch, the finance team handles reconciliation manually — pulling settlement files from the PSP, exporting internal transaction records, and matching them in Excel or Google Sheets. It takes an hour or two per day and feels under control. Then transaction volumes grow. A second payment provider is added. Multi-currency flows kick in. Chargebacks, partial refunds, and tiered fee structures enter the picture. The sheet that once worked fine becomes a 40-tab monstrosity that only one person understands — and breaks every time that person is on holiday.
According to Kani's Payments Reconciliation & Reporting Survey 2025, spreadsheet-based processes were still a cornerstone for 56 per cent of the 250 UK payments businesses surveyed — and a staggering 94 per cent of those were struggling to meet reporting deadlines. That is not a coincidence. The two facts are directly connected.
It is estimated that reconciliation issues contribute to more than 20% of operational hurdles in fintech firms, significantly throttling their growth potential. The hidden cost is not just analyst time — it is the capital cost of undetected discrepancies and the compliance cost of delayed or inaccurate reporting.
Payment reconciliation in fintech is the automated process of verifying operational truth by matching internal transaction records against external data from PSPs, banks, and networks. Unlike traditional finance, which might compare a bank statement once a month, fintech reconciliation operates continuously and at transaction-level granularity — managing high-velocity variables including gross-to-net settlements, FX spreads, tiered fee structures, and asynchronous events like chargebacks and partial refunds.
This is precisely why a spreadsheet cannot solve the problem past a certain volume threshold. It is not a matter of making the spreadsheet better. The architecture is fundamentally wrong for the job.

📺 Watch: How to Prepare a Bank Reconciliation

What "Proper" Payments Reconciliation Analytics Actually Looks Like
The right architecture for payments reconciliation is not a single tool — it is a data pipeline design pattern. Here is how we approach it in practice.
Layer 1: Ingestion and normalisation
Raw data arrives from multiple sources in incompatible formats: settlement CSVs from Stripe or Adyen, bank statement feeds, internal transaction logs from your ledger or core system. The first job is to land all of this into a central data warehouse — BigQuery or AWS Redshift, depending on the existing stack — and normalise it into a consistent schema. This sounds unglamorous, but it is where most reconciliation projects fail. Payment providers use different terminology, different timestamp conventions, different ways of representing fees, and different delay windows for settlement. Building a canonical transaction model that maps all of these to a shared standard is the foundational engineering work.
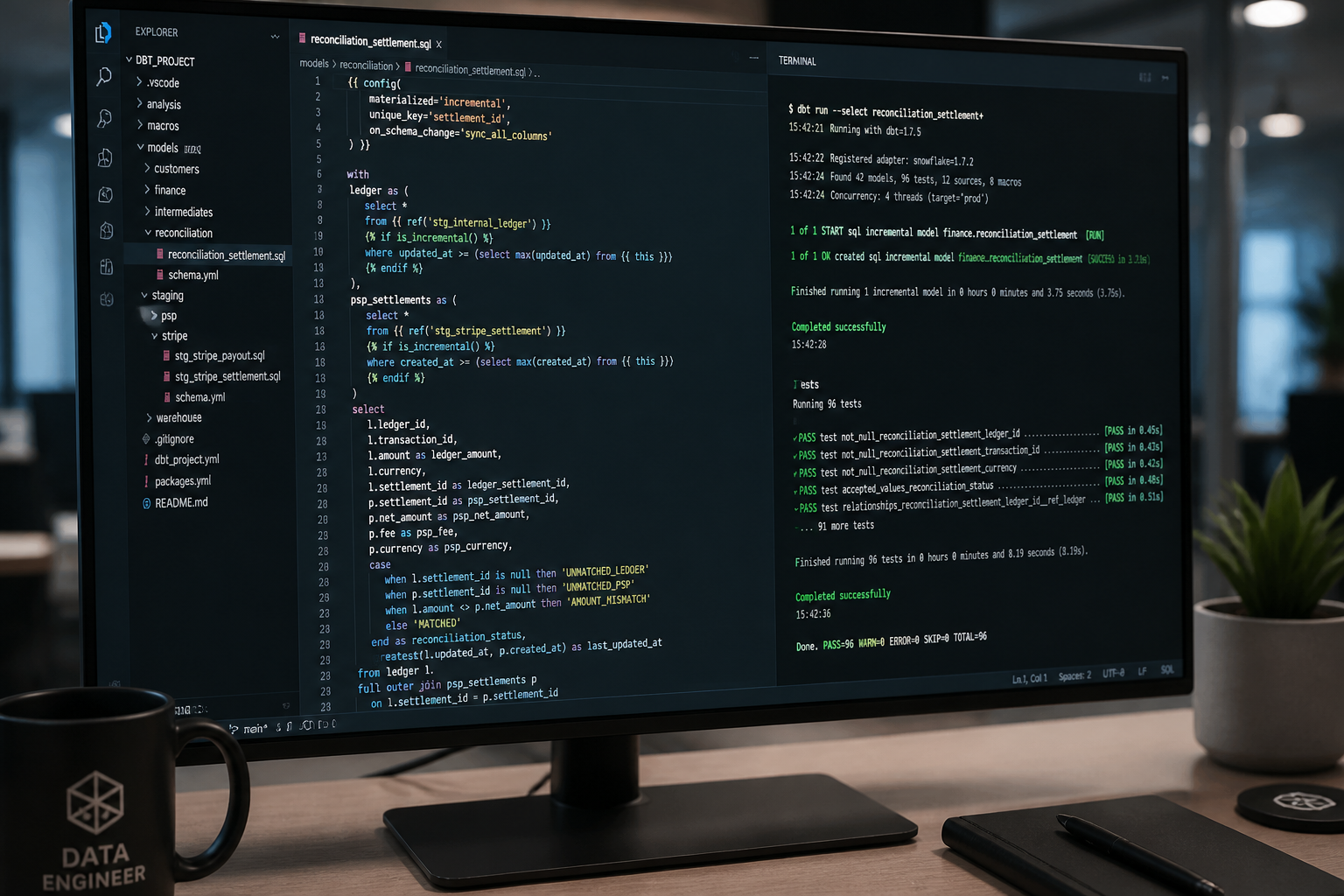
Layer 2: Matching logic in dbt
Once data is normalised, the matching logic lives in dbt models. A reconciliation model does one thing: it joins internal records to external records and classifies each pair as matched, unmatched-internal (you recorded it, they did not), unmatched-external (they recorded it, you did not), or mismatched-amount (both sides exist but values differ). Each of these categories has a different operational response — which is why the classification matters as much as the matching itself.
A pattern we see repeatedly in early-stage companies is that someone has attempted to do this matching in Python scripts that run ad hoc, or worse, in a spreadsheet VLOOKUP chain. The problem with both approaches is that they are not version-controlled, not testable, and not auditable. Moving this logic into dbt gives you all three — plus the ability to run it on a schedule and have finance teams query the results directly.
Layer 3: Exception management and alerting
A reconciliation pipeline that silently produces a list of mismatches nobody looks at has failed. The output needs to route exceptions to the right people at the right time. We typically implement this as a combination of a BI dashboard — built in Holistics or Looker — showing live exception counts, aging, and trend, plus automated alerting for exceptions above a defined value threshold or age threshold. Mature reconciliation is not defined by the absence of mismatches, but by how quickly they are resolved — with continuous real-time matching replacing batch processing, and exception queues with explicit aging rules governing the response workflow.
If you are looking to implement this kind of architecture in your payments business, explore how Fintel Analytics approaches reconciliation data engineering — we design and deliver exactly this kind of solution for fintech and payments companies globally.
The Real Cost of a Reconciliation Gap
Most founders treat reconciliation errors as a finance admin problem. The ones who have been through a capital reconciliation project tend to see it very differently afterwards.
We rebuilt the reconciliation pipeline for a global fintech where the existing process — a combination of manual spreadsheet matching and a partially automated script — was producing a running discrepancy that nobody could pin down. When we migrated the logic into a proper dbt model running against their BigQuery warehouse, we uncovered a $25 million discrepancy in their capital position that had gone undetected across multiple reporting cycles. At market borrowing rates, that gap was costing over $6,000 per day. The reconciliation process itself had been taking 30–50 minutes to run each time it was executed manually; the automated SQL pipeline now completes in under 3 seconds.
This is not an edge case. Precision is the bedrock of fintech. Yet manual reconciliation is plagued with a 15% discrepancy rate in financial reporting, showcasing the high cost of human error. At low transaction volumes, a 15% discrepancy rate is annoying. At Series A volumes — processing tens of thousands of transactions per day — it is a material financial control failure.
Fintech firms are losing an estimated 25,000 employee hours annually to manual reconciliation tasks — a burden that diverts developers from enhancing product features to address reconciliation issues. When we translate that into salary cost at a growth-stage company, the case for investing in a proper automated pipeline becomes straightforward.
How AI and ML Are Changing Transaction Matching
Rule-based matching — where you define exact match conditions and handle exceptions manually — works well up to a point. The problem is that payments data is inherently messy. Name variations between internal records and bank statements ("ACME Ltd" vs "ACME Limited"), fee deductions that alter settlement amounts, timing differences between authorization and settlement, split payments that need to be matched to a single invoice — these all create exceptions that rigid rules cannot handle without constant human intervention.
This is where machine learning adds genuine value in a reconciliation context. Traditional reconciliation relies on rigid rules and manual oversight. AI-powered reconciliation systems learn from your specific business patterns, continuously improving accuracy and reducing exceptions — through pattern recognition that identifies subtle transaction patterns rule-based systems miss, behavioral learning that adapts to unique vendor and customer payment behaviors, and predictive matching that anticipates likely matches before transactions are fully processed.
Implementing machine learning in reconciliation processes can cut errors by over 60%, as evidenced by fintechs that have adopted these technologies — with these systems not only streamlining current operations but also adapting to future changes, ensuring longevity and compliance amidst evolving regulations.
In practice, the ML layer does not replace the SQL matching model — it augments it. The dbt model handles the high-confidence exact matches. The ML model handles the fuzzy cases, scoring each potential match by probability and routing low-confidence matches to a human review queue rather than forcing them through a rule that may be wrong. This hybrid approach is both more accurate and more auditable than a pure ML black box — which matters enormously when a regulator or auditor asks you to explain why a transaction was matched the way it was.
Risk teams are shifting from reactive — investigating discrepancies after they happen — to predictive, using analytics to forecast exposure before transactions settle. That shift is only possible once the foundational reconciliation data layer is clean and automated.
Building a Reconciliation Data Model: A Practical Framework
For teams starting from scratch or rebuilding a broken process, here is the framework we use across delivery engagements:
Step 1 — Audit your data sources. List every system that generates or receives payment records: internal transaction database, PSP settlement reports (one per provider), bank statement feeds, chargeback and dispute logs, fee schedules. Document the schema, update frequency, and known data quality issues for each. This audit almost always surfaces a source that was missing from the previous reconciliation process entirely.
Step 2 — Define your canonical transaction model. Agree on a shared set of fields that every transaction record will map to: a unique internal transaction ID, a provider-side reference, an authorised amount, a settled amount, a settlement date, a currency, a status, and a fee amount. Every source table gets a staging model in dbt that transforms raw data into this canonical shape.
Step 3 — Build the matching model. Join staging tables on the agreed matching keys — typically a combination of provider reference, amount, and date window. Classify each record as matched, unmatched, or mismatched-amount. Add a column for match confidence score if using an ML layer.
Step 4 — Build the exception model. Filter for unmatched and mismatched records. Add aging (how many days has this exception been open?), value (what is the financial exposure?), and provider (which PSP or bank is the source of the break?). This is the table that powers your exception dashboard.
Step 5 — Instrument alerting. Set threshold-based alerts: any single exception above £X triggers a Slack notification to the finance lead; any exception aged beyond Y days triggers an escalation. An automated alerting system gives treasury teams real-time visibility into provider risk — reducing funding misses and giving leadership a quantifiable measure of capital efficiency.
Step 6 — Build the ops dashboard. Finance and treasury need a live view of: total matched vs unmatched volume, exception count by provider and age, net unreconciled value, and trend over time. This replaces the weekly manual report that took 90 minutes of analyst time with a live dashboard updated on each pipeline run.
For teams that have already built a partial solution, the audit at Step 1 is still the right starting point. We have yet to work with a growth-stage company where the audit did not surface at least one data source or edge case that was being silently ignored.
Frequently Asked Questions
Q: What is payments reconciliation analytics?
A: Payments reconciliation analytics is the use of automated data pipelines, SQL models, and dashboards to continuously match internal transaction records against external settlement data from PSPs, banks, and payment networks. It replaces manual spreadsheet-based matching with an always-on, auditable data layer that identifies discrepancies in near real-time and routes exceptions for resolution.
Q: How often should payments reconciliation run in a fintech?
A: For any fintech processing more than a few thousand transactions per day, reconciliation should run on an intraday or continuous basis — not end-of-day or weekly. The longer the lag between transaction and reconciliation, the harder it becomes to investigate and resolve exceptions. Modern data pipeline tooling makes intraday reconciliation straightforward once the underlying data models are in place.
Q: What is the difference between rule-based and AI-powered reconciliation matching?
A: Rule-based matching uses predefined conditions — exact amount, reference number, date — to match records. It is fast and auditable but fails on fuzzy cases: name variations, fee deductions, timing differences. AI-powered matching uses machine learning to score the probability of a match across these ambiguous cases, reducing the manual exception queue significantly. The best production implementations combine both: rules for high-confidence matches, ML for edge cases, and human review for anything below a defined confidence threshold.
Q: How do I build a reconciliation data model in dbt?
A: Start by staging each source — internal ledger, PSP settlement files, bank feeds — into a canonical transaction schema with consistent field names and types. Build a reconciliation mart model that joins these staging tables on your matching keys and classifies each record as matched, unmatched, or mismatched. Add exception and aging logic in a downstream model. Schedule the pipeline to run on your required cadence and surface outputs in your BI tool. Testing with dbt's built-in test framework is essential — particularly uniqueness and not-null tests on transaction IDs.
Q: What are the biggest risks of poor payments reconciliation in fintech?
A: The three main risk categories are: financial (undetected discrepancies that represent real capital exposure — we have seen single projects surface eight-figure gaps); compliance (regulators expect payment firms to demonstrate transaction-level financial controls, and manual processes cannot produce the audit trail required at scale); and operational (manual reconciliation does not scale — as transaction volumes grow, so does the error rate and the analyst time required, creating a bottleneck that constrains the whole business).
Building robust payments reconciliation analytics is one of the highest-leverage investments a growth-stage fintech or payments company can make — and one of the areas where weak data infrastructure most visibly translates into hard financial cost. At Fintel Analytics, we have helped fintech and payments businesses across multiple geographies design, build, and operationalise reconciliation data pipelines from first principles — from source system audit through to production dbt models, exception dashboards, and automated alerting. If your reconciliation process still depends on manual steps, scheduled exports, or a spreadsheet that only one person truly understands, that is a solvable problem — and solving it typically pays back the investment within the first quarter of operation.